Technical Shorts, not Technical Debt
When I was at Coinbase in 2017 we found ourselves going through hypergrowth with a codebase that had racked up quite a bit of tech debt. The results weren’t pretty: frequent outages, unhappy customers, and sleepless nights. We learned the hard way that a small part of our debt caused most of the problems. The trick lay in figuring out which part that was.
Let’s start with a definition: technical debt is taking a shortcut to move faster in exchange for some downside. It might create code that’s hard to understand or a site that crashes when traffic goes up. But technical debt is a misnomer because these shortcuts aren’t like loans at all. They behave like physical short-sells1. That’s when you borrow stock and sell it for money, with a promise that you’ll buy it back and return it next month. The distinction is important because you can lose finite amounts of money taking a loan, but infinite amounts with a short position.
Should you take a technical short position? The decision is easy for a young startup searching for product-market fit. Shipping the next feature could be the difference between raising money and death. The cost of downtime or a little productivity loss is insignificant 2. But engineering leaders at hypergrowth companies must deal with a very different calculus.
Technical shorts are reasonable trade-offs that become unreasonable with time. I say time, but it’s really the number of users or engineers you have. Growth increases the downside of shorts while capping their upside. So when is the right time to fix a short? To answer this, you must understand that there are different types of shorts—and that some grow faster than others.
Clunky Abstractions
Let’s say you’re working at a fast-growing ridesharing app about to launch in a new city. You need to know where drivers are so you add a city column. You can now do useful things like find and email drivers in San Francisco. Now drivers sign up in cities like Fresno but commute to drive in San Francisco and the city column can’t tell you who drives in San Francisco anymore. You have to look through a driver’s rides and reason about it. Teams take different approaches leading to different numbers for drivers in San Francisco. The problem is that location became a dynamic concept but its abstraction didn’t catch up.
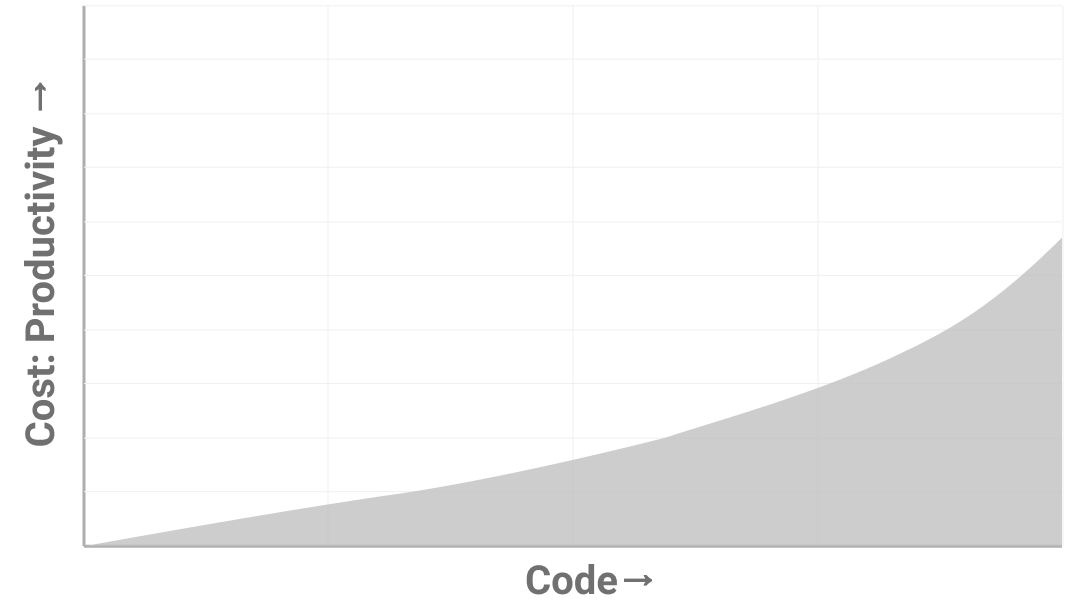
Clunky abstractions like this one impose an exponential tax. Their cost increases every time something new interacts with them. You’ll know you have them when your best engineers can’t deliver on time and when simple bugs are expensive to fix. The more things that clunky abstractions touch, the more exponentially painful they become. That’s actually a good way to prioritize - start with the ones that show up the most in code. The nice thing about abstraction shorts is that you control their growth. If things get really bad stop writing new features and go clean up your abstractions.
Aging Platforms
Let’s say you built your backend in Rails 5, and Rails 6 comes out. Should you upgrade? The conventional wisdom is no. It’s expensive and a few new features hardly seem worth the effort. But if you don’t upgrade two exponentially bad things happen. First, the upgrade gets more expensive every day as you write more code. Second, the people who wrote libraries for Rails 5 start moving to Rails 6.
It’s now two years in the future. You find a bug in your auth library and report it but no one fixes it. You have to fix it yourself. In fact, you have to fix everything yourself because no one writes code for Rails 5 anymore. You think about upgrading to Rails 6 but its now a multi-month cross-functional project that every manager dreads. You’re stuck between a rock and a very hard place.
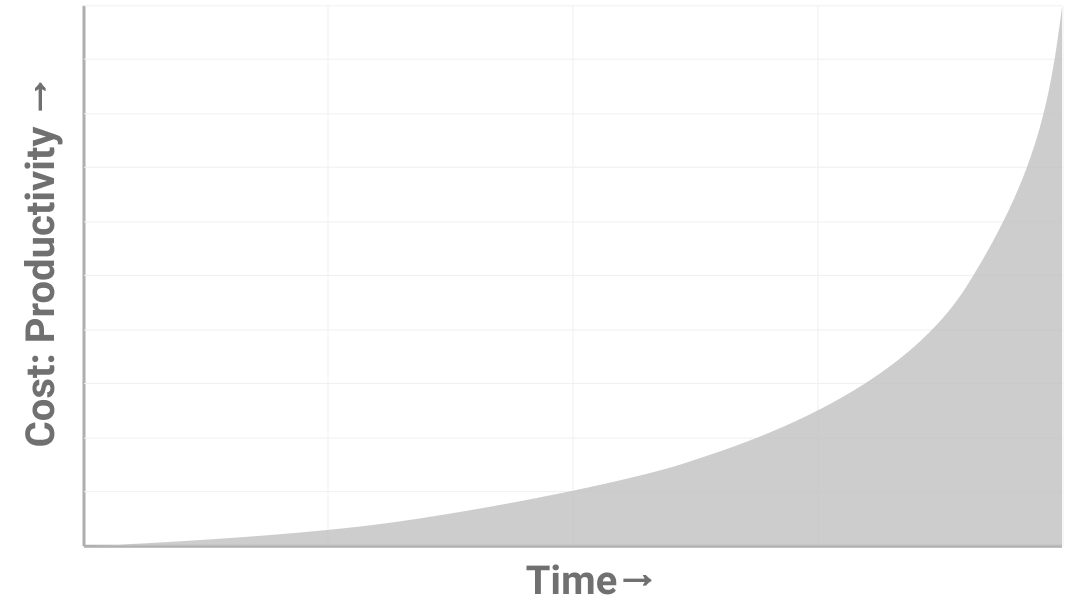
Platform shorts get worse with time but in a more exponential way than clunky abstractions. People don’t think of them as shortcuts because they happen by not doing anything at all. They are the only type of short driven by factors outside of your company. The best way to deal with them is to embrace upgrades. You must upgrade before the symptoms show up or it will be far too expensive. People who haven’t seen this play out before lack the conviction to do this. A good rule of thumb is to upgrade 6 months after a big release. That keeps you off the bleeding edge but on the right side of the exponential growth curve.
Hidden Bottlenecks
You’re tasked with off-boarding bad drivers every week. You write a job that averages ratings but run it after midnight on Tuesday because it’s a big query. Everything goes fine until New Year’s which falls on a Tuesday. The job runs during peak traffic, takes down the app and becomes a PR nightmare. Successful companies have codebases littered with bottlenecks like this. They’re notorious for kicking up at the same time under heavy traffic which isn’t a factor you can control. Users use your product when they want to, and it’s generally bad business to tell them that they can’t.
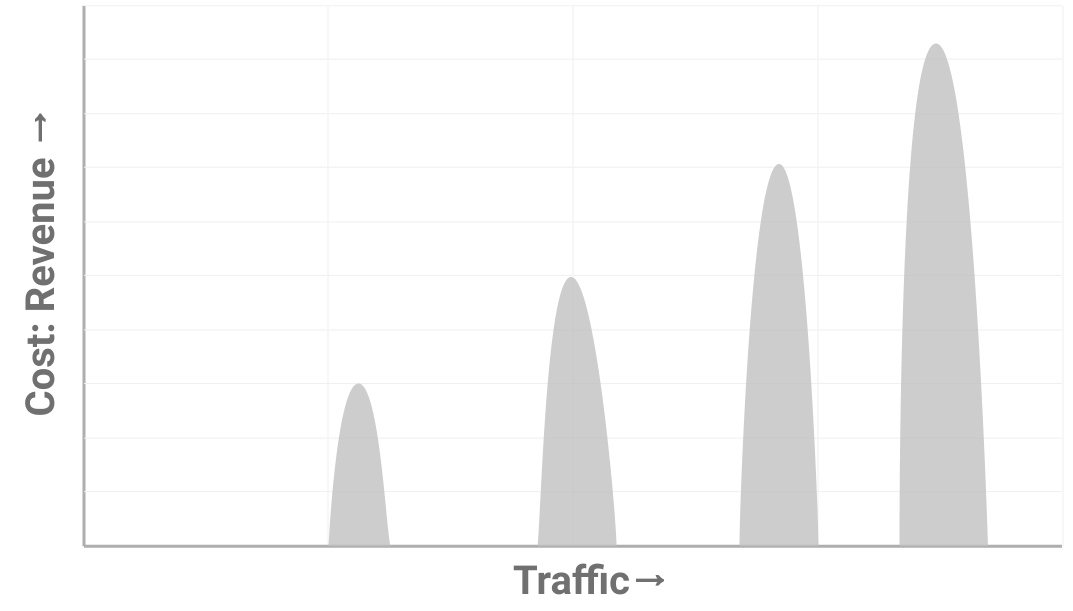
The mistake that most teams make is treating symptoms instead of the cause. You can fix an outage by adding a database index but you can only prevent outages by creating a system that doesn’t let you forget indexes. If you fall into the trap of treating symptoms, you’ll find that bottlenecks happen more often and cause more damage.
The first step to recovery is understanding that you must move from build mode to scale mode. You’re not adding features anymore, you’re in the business of fixing bottlenecks to give yourself breathing room to execute. Depending on your situation you may be here for days or months. You’ll need to invest in infrastructure like early warning systems and design reviews. Start early because changing people’s habits is much harder than changing code.
Fault Intolerance
Drivers get paid weekly, so every Sunday night a job calculates the payouts and sends them to the bank. If it doesn’t see a rejection message from the bank on Monday, it assumes everything went through. This is actually how many banks operate. One day the bank gets overwhelmed and uploads the file very late. The job looks on Monday, sees no rejection, and assumes all the payments went through. Until the drivers call to complain everyone is blissfully ignorant of the problem.
Fault intolerance happens when you don’t predict edge cases and program in ways to handle them. The system might throw its hands up and complain until an engineer fixes it. Or it might not complain and let the errors pile up. Silent errors in systems like payments can be very bad news. These types of problems get exponentially worse with traffic because things break in ways you can’t predict.
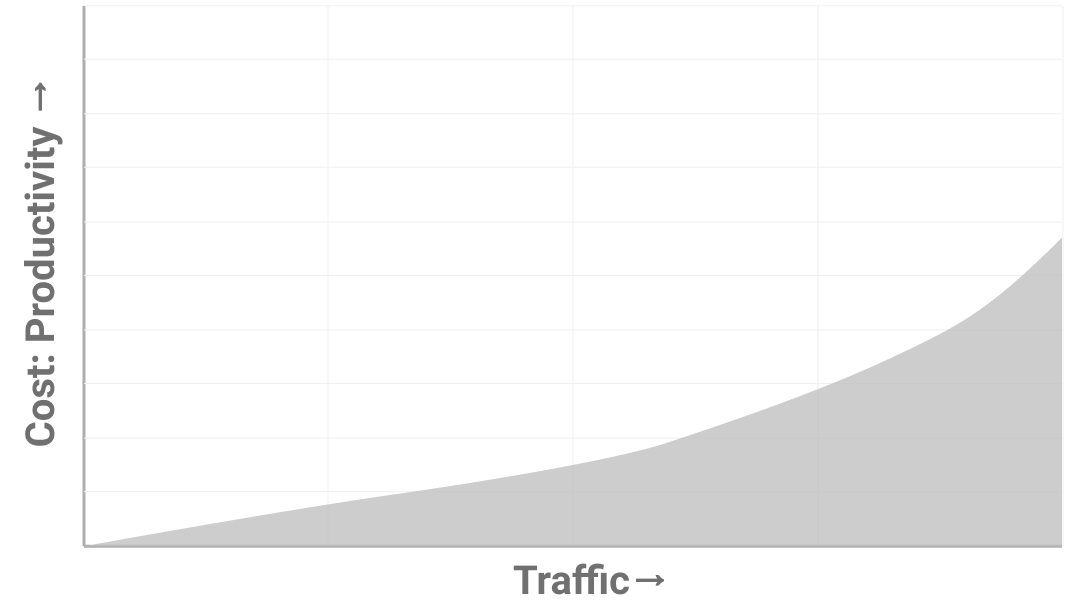
A simple way to identify fault intolerance is to see where issues crop up if your engineers can’t use their laptops for a day. Another way is to look for things that senior engineers worry about changing. A third way is to reason from first principles about assumptions underlying your systems and why they might not always be true.
Fault intolerant systems tend to carry tail risk. This is a fancy way of saying that most issues are trivial but one in ten thousand might kill the company. If you were looking at the average badness you would conclude that it’s not worth fixing. Instead, brainstorm a list of all possible failures, give each one a cost in dollars and take the average of the 3 worst ones3. If the cost of fixing the system is greater than this amount, it might be safe to ignore.
We’ve talked about four types of shorts so far: clunky abstractions, aging platforms, hidden bottlenecks and fault intolerance. Can you map these patterns and growth curves onto your codebase? Or find new types that have different curves? It might change your perspective on which short you need to fix next.
Thanks to Keith Adams, Tomas Barreto, Noah Levin and Shaun Young for help with drafts.
Inspired by Bad code isn’t Technical Debt, it’s an unhedged Call Option. ↩
There are some industries like aerospace and medicine, where this isn’t true to the same degree. ↩
Inspired by the Expected Shortfall risk measure. You can also use eng hours or any other number instead of dollars. ↩